
This blog post is part of a mini‑series showcasing select projects being built at Grass, giving a look at the engineering challenges we face and how we solve them to improve the network. This work is supported by engineers at Wynd Labs, which is a core contributor to Grass.
Customers don’t just need more data, they need data shaped for specific tasks. Grass is applying machine learning to improve how data is labeled and filtered, allowing customers to access exactly what they need without complex one‑off pipelines. This work is one step toward unlocking seamless, high quality data access at scale.
The advantage of large data repositories is not just the quantity of data, but their multi-modality as well. Customers (especially AI labs) often require shaped, specific sets of data for their specific tasks. To meet that need, Grass has explored systems that detect movement and spatial orientation in video using pre-existing, pre-trained models. Using these tools is one of many steps Grass is taking towards making ML-powered labeling a core part of how customers access video datasets.
Grass’s solution in the past has been to create bespoke pipelines and scraping efforts to accommodate these requests. But this is often expensive, and engineers have to be tied up meeting specific requirements instead of working on higher-leverage problems. Solutions like rudimentary metadata filtering don’t align well enough with customer demands.
Machine learning offers the most scalable and accurate way to meet client-specific requirements.
Data labelling with machine learning provides a more scalable and often more effective means of providing customers high quality data in specific domains. With machine learning, Grass can cut to the heart of what the data actually represents over more shallow qualities– like actions being done, languages being spoken, and who is speaking them.
The work with video frame analysis and orientation estimation represents the first step in this. By detecting relevant features and their positioning, Grass can effectively provide data that is useful to those looking to do work on conversational data– a prevalent category in deep vision models.
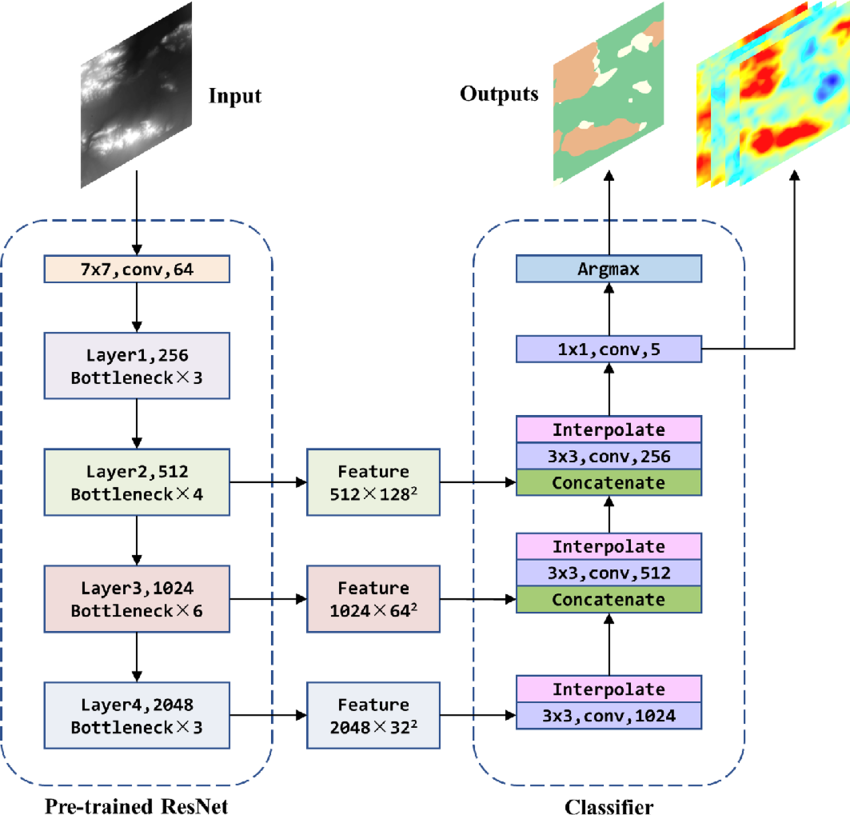
Grass sees this as a touchstone for what’s to come, with future work including clustering and new modality like audio. The data itself is only part of the product; how customers interface with curated, shaped samples is just as important. Grass’s goal is to make integration with multimodal data seamless and scalable as customer needs evolve.
- Aidan Erickson, Machine Learning Research Engineer at Wynd Labs

